If you spent the last decade in cloud engineering, you have probably watched the FinOps discipline mature in front of you. From spreadsheet-driven cost reviews in 2015, to dedicated tooling in 2020, to executive-level visibility today. The discipline has grown up.
And yet, walk into any platform engineering team in 2026 and ask a simple question: "Did you look at your cost dashboard this week?"
Most will hesitate. Some will admit they did not. A few will tell you the dashboard exists, somewhere, and that someone in the finance team probably looks at it.
The State of FinOps 2026 report, published by the FinOps Foundation a few weeks ago, captures this paradox better than any other industry document I have read this year. With 1,192 respondents representing over 83 billion dollars in annual cloud spend, it is the most authoritative snapshot of the discipline available.
And buried in its 60 pages is a sentence that stopped me cold:
"Dashboards are table stakes of yesterday, reactive. You have to move to proactive, real-time, automation."
The quote comes from a practitioner. The Foundation chose to feature it in its editorial pull-quotes, which is its way of saying: we agree.
This article is a reading of what the report tells us, what it does not say out loud, and why I believe the next breakthrough in cloud-native cost intelligence will not come from better dashboards. It will come from a fundamentally different interface.
The first paradox: cost is the number one Kubernetes challenge, but few teams act on it
Let us start with the numbers everyone agrees on.
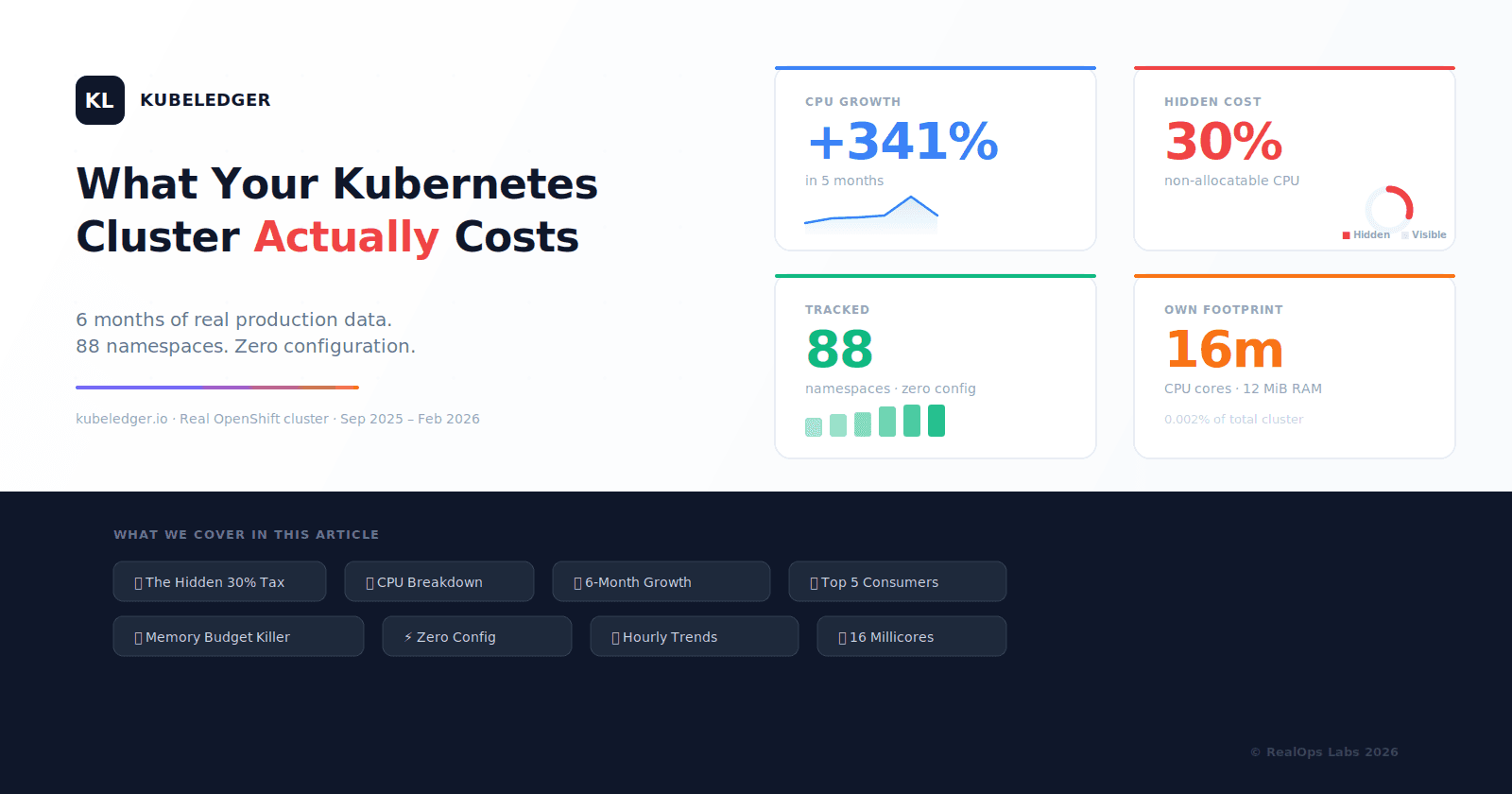
Cost is now the top challenge in Kubernetes operations. Spectro Cloud's 2025 State of Production Kubernetes report, surveying 455 platform engineers, places cost as the number one operational concern, ahead of security and complexity, with 88 percent of organizations reporting year-over-year total cost of ownership growth.
The State of FinOps 2026 echoes this trajectory from a different angle: 98 percent of respondents now manage AI spend, up from 31 percent two years ago. Compute costs have exploded, GPU costs have exploded, and the discipline that was supposed to keep them in check is, by the practitioners' own admission, struggling to scale.
But here is what nobody talks about in those numbers. The data exists. The metrics are collected. Prometheus has been scraping cluster telemetry for nearly a decade. Cloud providers have detailed billing APIs. Open-source projects like OpenCost, Kubecost, and KubeLedger have been turning that raw telemetry into structured cost data for years.
The bottleneck is not data collection. The bottleneck is something else entirely.
The second paradox: insights exist, but they do not reach the people who decide
The Foundation's report makes a quiet but striking observation about the organizational shift that happened in the last three years. In 2023, the typical FinOps team reported to the CFO. In 2026, 78 percent of FinOps teams report to the CTO or CIO. The CFO rattachement has collapsed to 8 percent.
This is not a cosmetic change. It signals that FinOps has stopped being a finance function and become a technical leadership function. The people responsible for cloud spend are now the same people responsible for architecture decisions, platform reliability, and engineering velocity.
Now consider what that means for tooling. The traditional FinOps dashboard was designed for a financial analyst reading a monthly report. Tabbed views, drill-down filters, exportable CSVs, monthly true-ups. Useful, but slow. A CTO does not have time to learn the dashboard's UX every Monday morning. A Head of Platform Engineering does not want to click through six filter dropdowns to find out which team blew the budget last quarter.
So what do they do? They ask someone. They ping the FinOps lead on Slack. They wait. They get a screenshot. They forward it to their boss.
That round-trip is the bottleneck. Not the data. Not the dashboards. The interface between the data and the decision.
The third paradox: AI is everywhere in FinOps, except where it would matter most
This is where the 2026 report becomes really interesting. The Foundation lists, among the top emerging use cases for AI in FinOps:
Anomaly detection and faster alerting
Automated right-sizing
Natural language querying of cost data
Automated procurement of discount instruments
Automated tagging to accelerate allocation
The third item is the one that should make every FinOps tool builder pause.
For two years, the industry has been bolting AI features onto existing dashboards. A chatbot in the corner of the screen. An "AI insights" tab that summarizes what the human could read anyway. A recommendation engine that suggests right-sizing actions the team will probably ignore. All of these are AI added to the existing interface.
What the Foundation's report identifies is something else. It is the recognition that the interface itself should change. That asking "which namespaces drove our CPU growth last quarter?" in plain English is not a feature, it is the new primitive. And that the entire workflow of cloud cost intelligence should be rebuilt around conversational, contextual, just-in-time queries, rather than around static dashboards that nobody opens.
This is not science fiction. The protocol layer to make this possible already exists. It is called the Model Context Protocol.
Why MCP changes the equation
The Model Context Protocol, introduced by Anthropic in late 2024 and adopted with surprising speed by the broader ecosystem, is a standard for connecting language models to data sources. It is to AI assistants what the Language Server Protocol was to code editors a decade ago: a way for any tool to talk to any client, without bespoke integration.
Concretely, an MCP server exposes a set of read-only tools that describe what the data is, how to query it, and what to do with the result. The language model becomes the orchestrator: it picks the right tool, parses the parameters, calls the server, and interprets the response in the conversation. The data layer stays clean, the narrative layer stays in the AI client, and the user never has to learn a query language.
For cloud cost data, this is transformative. Not because LLMs are magical, they are not, but because the interface friction disappears. When the cost data is sitting behind an MCP server, any tool that speaks MCP can query it. Claude Desktop, Cursor, Mistral's Le Chat, custom internal assistants. The same data becomes accessible from wherever the engineer happens to be working.
This is not theory. This is what I just shipped with the KubeLedger MCP server.
What this looks like in practice
KubeLedger has been collecting and structuring Kubernetes cluster telemetry for years. The new MCP server adds a thin conversational layer on top of that data. Ten read-only tools exposing namespace usage, top consumers, breakdown with cluster overhead separation, efficiency ratios with descriptive classification, hourly trends, period comparisons, and group aggregation by glob pattern.
When you ask, in plain English: "What's the cost concentration across our cluster?", the language model decides to call the get_namespace_breakdown tool. The KubeLedger server returns structured data with the breakdown, the concentration metrics (top-3 share, top-10 share), and a separate cluster_overhead block for the non-allocatable capacity. The language model formats the answer in a readable summary, but the underlying data is auditable, traceable, and deterministic.
A few design choices deserve emphasis, because they matter for trust:
Read-only by design. The MCP server never writes, never modifies, never takes action. It exposes data. The narrative intelligence lives in the AI client, where it belongs.
No embedded LLM. KubeLedger does not bundle a language model. The server is a descriptive surface. The model is chosen by the user, and can be Claude, Mistral, a self-hosted Llama, or anything else that speaks MCP.
Provenance for every response. Every tool call returns a metadata block with the cost model, the data window, the source file, and a freshness warning. Nothing is opaque. A skeptical engineer can verify exactly where every number came from.
Descriptive, not prescriptive. The efficiency classification surfaces three labels (over-provisioned, balanced, under-provisioned) with documented thresholds. It never tells you what to do. The decision stays human.
These choices are not accidental. They are a deliberate counter-position to the wave of "AI-powered FinOps" products that promise actionable recommendations, automated remediation, and predictive savings. Those products may eventually deliver on their promises. But in 2026, what most platform teams need is not more automation. It is clearer access to the data they already collect.
What the FinOps Foundation report does not say out loud
Reading between the lines of the report, three observations emerge that I think will shape the next two years of FinOps tooling.
First, pre-deployment cost estimation will become a battleground. The report identifies "pre-deployment architecture costing" as the number two most-requested capability missing from current tooling. Practitioners are building it themselves with home-grown scripts and adapted IaC scanners. None of the existing commercial platforms handle Kubernetes manifests natively. Whoever cracks this first, integrating real cluster utilization patterns into PR review comments, owns the next phase of shift-left FinOps.
Second, the optimization era is over. As one advanced practitioner is quoted in the report: "I haven't been focused on optimization as priority one for a long time." The big rocks of waste have been picked. The remaining gains require disproportionate effort. The next wave of value comes from governance, allocation, and shaping spend before it happens, not from squeezing the last five percent out of existing workloads.
Third, the Single Pane of Glass is finally a real demand, not just a marketing line. The report lists it as the number three most-wanted capability. Practitioners want one place to see cloud, SaaS, licensing, private cloud, and data center costs together. Vendor consolidation will accelerate. So will the temptation to lock teams into proprietary platforms. The open-source response to that consolidation matters.
The deeper question: where does your cost data go?
There is one dimension the Foundation's report does not address, but that I find increasingly hard to ignore.
When you query your Kubernetes cost data in natural language through a commercial AI-powered FinOps platform, where does that telemetry actually go? Whose model processes it? Under which jurisdiction? With what guarantees about retention, training, and access?
For regulated sectors in Europe, finance, healthcare, defense, public sector, this question is not abstract. NIS2 demands traceable data flows. SecNumCloud requires data residency. The EU AI Act adds governance obligations on high-impact AI usage. DORA imposes operational resilience requirements on financial entities.
The conversational layer for FinOps cannot be a black box hosted in a foreign jurisdiction. It needs to be self-hostable, LLM-agnostic, and built on open standards. This is not a French paranoia, it is a structural requirement for any tool that aspires to enterprise adoption in Europe in 2026 and beyond.
This is why KubeLedger MCP is open-source, self-hostable, and designed to run inside your cluster, your VPC, your air-gapped environment. The data never leaves your perimeter unless you choose to send it somewhere. Pair it with Claude if you trust Anthropic. Pair it with Mistral if you prefer European sovereignty. Pair it with a self-hosted Llama if you need full isolation. The choice is yours, and the architecture supports all three equally.
What I am betting on
The State of FinOps 2026 report is, in my reading, the moment the industry collectively realized that the next phase of cloud-native cost intelligence will not come from better dashboards. The discipline has matured past that point.
What comes next is a layer of conversational, contextual, just-in-time access to cost data. Not as a feature, but as a primitive. Not as a chatbot bolted onto an existing platform, but as an open protocol that any client can speak. Not as a hosted SaaS that processes your telemetry in someone else's cloud, but as a self-hostable component that runs where your data lives.
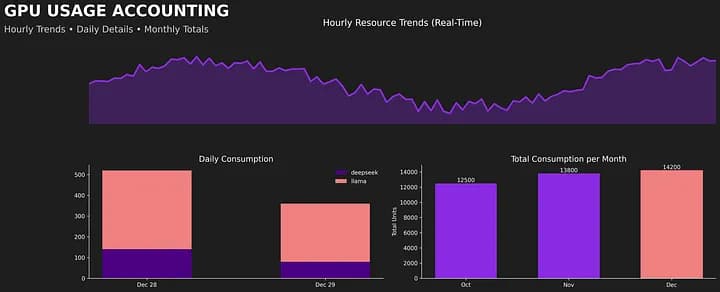
The KubeLedger MCP server is one bet on that future. It is open-source, it is live today, and it works on real production clusters. The first ten tools cover the descriptive layer: usage, concentration, efficiency, trends, comparisons, groupings. The next layer, GPU intelligence and pre-deployment cost estimation, is on the roadmap.
If you are running Kubernetes at scale, and you are tired of the dashboard-screenshot-Slack roundtrip, I would love to hear what your first question to your cluster would be.
You can find the project on GitHub, the spec is fully documented, and the MCP server runs in any Kubernes environment: https://github.com/realopslabs/kubeledger.
The bottleneck is no longer the data. It is the interface.
It is time we built a better one.